ALTER, index, DCL, 정규화
2024. 2. 28. 01:30ㆍBackend 취업준비/SQL
ALTER
- 기존에 있는 테이블의 구조를 변경하기 위해 사용
- 테이블에 데이터가 쌓여있는 상태에서 구조를 변경하면 예기치 못한 이슈가 발생할 수 있으니 신중하게 사용해야 한다
- 새로운 열 추가
ALTER TABLE students ADD grade VARCHAR(20)
- 기존 열 이름 변경
ALTER TABLE students RENAME COLUMN grade TO score
- 기존 열 데이터 타입 변경
ALTER TABLE students ALTER COLUMN address TYPE VARCHAR(100)- 데이터 유실의 위험
- 문자열 데이터를 숫자로 변경하는 경우 데이터의 손실이 발생할 수 있다.
- "123"이라는 문자열을 숫자로 변경하려고 해도 오류가 난다
- 제약 조건 위배
- 기존 열의 데이터 타입을 변경하면 해당 열에 적용된 제약 조건이 위배될 수 있다.
- 열의 데이터 타입을 변경하여 최대 길이 제약 조건을 초과하는 데이터가 있을 수 있다.
- 열 삭제
ALTER TABLE students DROP COLUMN grade
DROP vs TRUNCATE vs DELETE
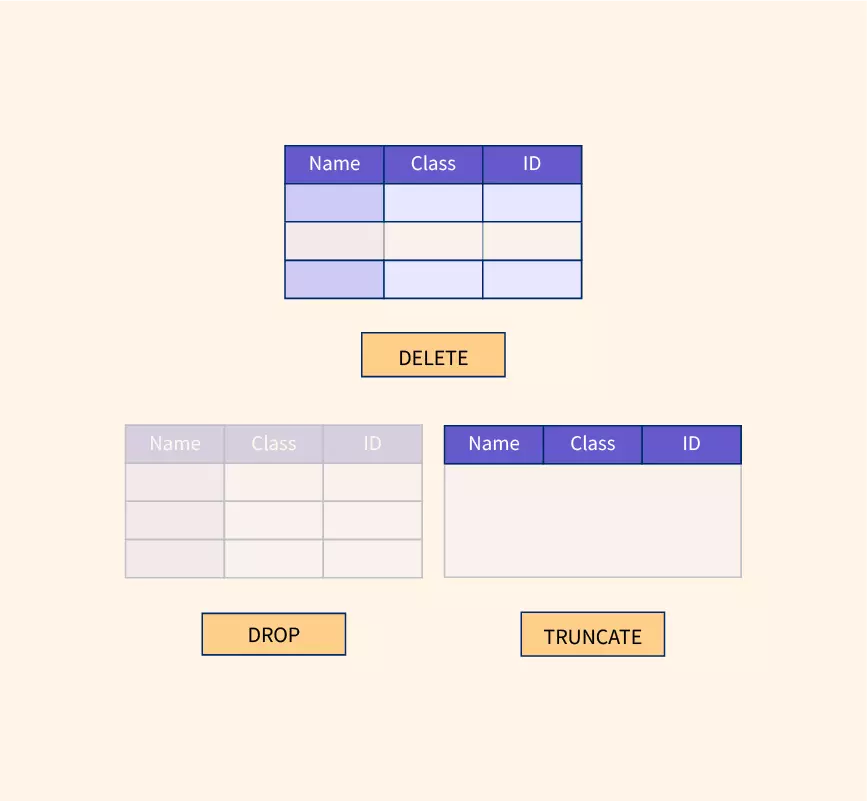
| DROP | TRUNCATE | DELETE | |
| 종류 | ddl | ddl(일부dml) | dml |
| commit | auto commit | auto commit | 사용자 commit |
| rollback | 불가 | 불가 | 가능 |
| 명령어 수행시 | 테이블 정의 삭제 | 테이블을 최초 생성한 상태로 만들어줌 | 데이터만 삭제 |
| 로그 | 남기지 않음 | 남기지 않음 | 남김 |
| 속드 | 빠름 | 빠름 | 느림 |
index
- 테이블의 특정 열에 대한 검색 및 조회 성능을 향상 시키기 위해 사용되는 자료구조
- 인덱스가 없다면 원하는 데이터의 위치를 특정할 힌트가 없다보니 테이블 전체를 탐색(Full Scan)해서 데이터를 찾아야겠지만, 인덱스가 있다면 전체를 탐색하지 않고도 필요한 행에 빠르게 접근
Index 생성/삭제 문법
생성/추가
-- 단일 컬럼 인덱스
CREATE INDEX [인덱스명] ON [테이블명] ([컬럼명]);
-- 다중 컬럼 인덱스
CREATE INDEX [인덱스명] ON [테이블명] ([컬럼명, ...]);
삭제
ALTER TABLE [테이블명] DROP INDEX [인덱스이름];
index자료구조
- hash table
- 해시 함수는 Key가 조금이라도 다르면 완전히 다른 해시 값을 생성.
- 이러한 해시 테이블을 사용하는 Index의 경우 WHERE 조건의 등호(=) 연산에는 효율이 좋지만, 부등호 연산(>, <)은 부적합 하다.
- 해시 테이블은 내부 데이터들이 정렬되어 있지 않아 탐색이 효율적이지 않다
- PostgreSQL은 B-tree, Hash, GIST, SP-GiST, GIN, BRIN 그리고 bloom 확장자 등 여러 개의 인덱스 유형을 제공
- 각 인덱스 유형들은 다양한 유형의 쿼리에 가장 적합한 알고리즘을 사용
- 기본적으로 CREATE INDEX 명령어를 사용하면 B-tree 유형으로 생성되는데 그 이유는 일반적으로 가장 많은 상황에서 적합한 알고리즘이기 때문
- 다른 인덱스 유형을 선택하려면 USING 키워드를 사용
index 사용하기
- index ⇒ 인덱스 테이블에서는 데이터를 정렬하면서 삽입, 삭제, 수정이 이루어지기 때문에 전체적인 성능 저하를 초래할 수 있다
- 조회 작업에 이용되는 것이 유리
- 카디널리티(Cardinality)는 특정 데이터 집합의 유니크(Unique)한 값의 개수.
- 즉, 중복도가 '낮으면' 카디널리티가 '높다'고 표현. 반대로 중복도가 '높으면' 카디널리티가 '낮다'고 표현
- 일반적으로 카디널리티가 높을 수록 인덱스를 생성하는 것이 유용
DCL
GRANT, REVOKE에서 부여하고 박탈할 수 있는 권한의 종류
SELECT 조회 권한
| UPDATE | 수정 권한 |
| INSERT | 삽입 권한 |
| DELETE | 삭제 권한 |
| ALL | 모든 권한 |
- 데이터베이스를 다룰 수 있는 권한을 부여하거나 박탈
- grant
- revoke
- 트랜잭션(Transaction)을 관리
- commit
- rollback
정규화
관계형 데이터베이스 설계 시 중복과 갱신 이상을 최소화하기 위해서 데이터를 구조화 하는 작업
- 정규화가 진행되면 기존 릴레이션이 분해된다
- 분해된 릴레이션은 무손실 조인을 보장해야 한다. 분해된 릴레이션을 하나로 합쳤을 때 정확히 원래의 정보들이 나와야 한다
- 함수적 종속성을 보존해야 한다
함수적 종속성
- 속성X의 값이 속성Y의 값을 유일하게 결정한다면
- X가 Y를 결정한다라고 표현
- Y가 X에 함수적으로 종속되어 있다고 표현
- X → Y로 표현(X는 결정자, Y는 종속자)
- 함수 종속 관계 판단 시 유의 사항
- 속성 값은 계속 변할 수 있으므로 현재 relation에 포함된 속성 값만으로 판단하면 안됨
- Primary Key와 Candidate Key는 Relation의 다른 모든 속성들에 대해 결정자가 된다(PK와 CK는 unique하기 때문)
- Primary Key나 Candidate Key가 아닌 속성들도 다른 속성 값을 유일하게 결정한다면 얼마든지 결정자가 될 수 있다
완전 함수적 종속성
- 어떤 테이블 R에서 속성 Y가 속성 집합 X 전체에 대한 함수적 종속성을 가지면서, 속성 집합 X의 어떠한 진부분 집합 Z에는 함수적 종속성이 없다는 것을 의미
- "진부분 집합"이란 X 자체가 아닌, X에서 속성을 하나 이상 제거한 집합을 의미
- 이 정의는 속성 Y가 속성 집합 X에 완전 함수적으로 종속되어 있을 때, X의 어떠한 진부분 집합에도 Y가 종속되지 않는다는 것을 강조
부분 함수적 종속성
- 어떤 테이블 R에서 속성 Y가 다른 집합 X 전체에 대해 함수적 종속성을 가지면서, 속성 집합 X의 임의의 진부분 집합에 대해서도 함수적 종속성을 가질 때, 속성 Y는 속성 집합 X에 부분 함수적 종속성을 가진다고 말한다
- 즉 Y가 X의 전체 속성에만 종속되는 것이 아니라, X의 일부 속성 만에도 종속되는 경우
이행 함수적 종속성
- 이행 함수적 종속성은 함수적 종속성의 확장으로, 두 개의 속성이 간접적으로 다른 속성에 종속되는 경우를 나타낸다
- 즉, X → Y, Y → Z인 종속 관계가 있을 때 X → Z도 성립하는 경우 (성립 안 할 수도 있나?)
정규화
- 제 1 정규화
- 릴레이션의 모든 속성이 원자값만을 가질 때
- 간단히 얘기하면 테이블 분할과 기본키 지정
- 제 2 정규화
- 릴레이션이 제1 정규화를 만족하며, PK가 아닌 모든 속성이 PK에 완전 함수적 종속성을 가질 때
- 간단히 얘기하면 기본키에 중복이 없는지 검사 후 분리
- 제 3 정규화
- 릴레이션이 제 2 정규화를 만족하며, PK가 아닌 모든 속성이 PK에 이행 함수적 종속성을 가지지 않을 때
- 간단히 얘기하면 기본키 이외의 부분에서 중복이 없는지 검사 ex) 같은 사람이 반복해서 주문하면 사람에 고객번호를 할당하며 테이블을 분리해 준다. 기존 테이블엔 사람명 대신 고객번호가 들어가는 형식. 성명에 동명이인의 가능성을 생각하면 분리하는 것이 효과가 있음을 알 수 있다.
장점
- 목적 한마디로 정리 => 하나의 데이터가 한 곳에 저장되어 있도록 하기 위함.
- 데이터 안정성 유지
- 중복, null값이 줄어든다
- 이상 현상 제거
- 저장 공간 최소화
단점
- 릴레이션의 분해로 인해 join연산이 많아진다
'Backend 취업준비 > SQL' 카테고리의 다른 글
| JOIN, UNION, 데이터베이스 생성하기 (2) | 2024.02.27 |
|---|---|
| SQL 기초 (0) | 2024.02.24 |